
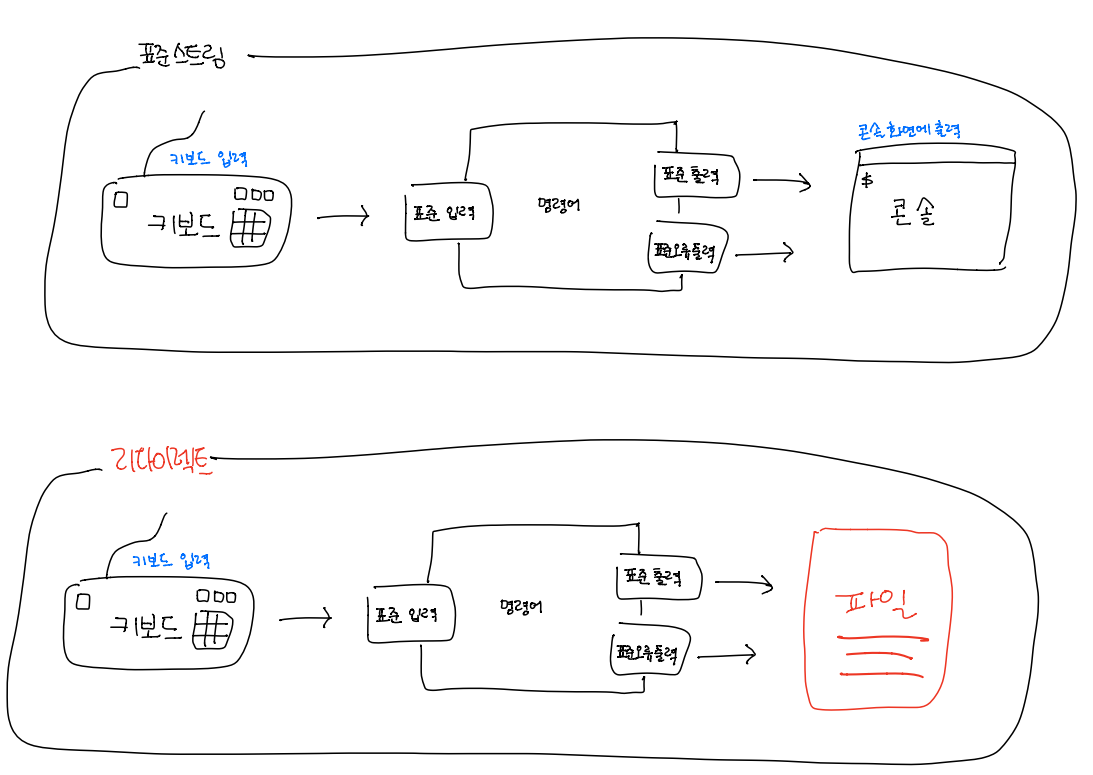
1. 표준 스트림과 리다이렉트
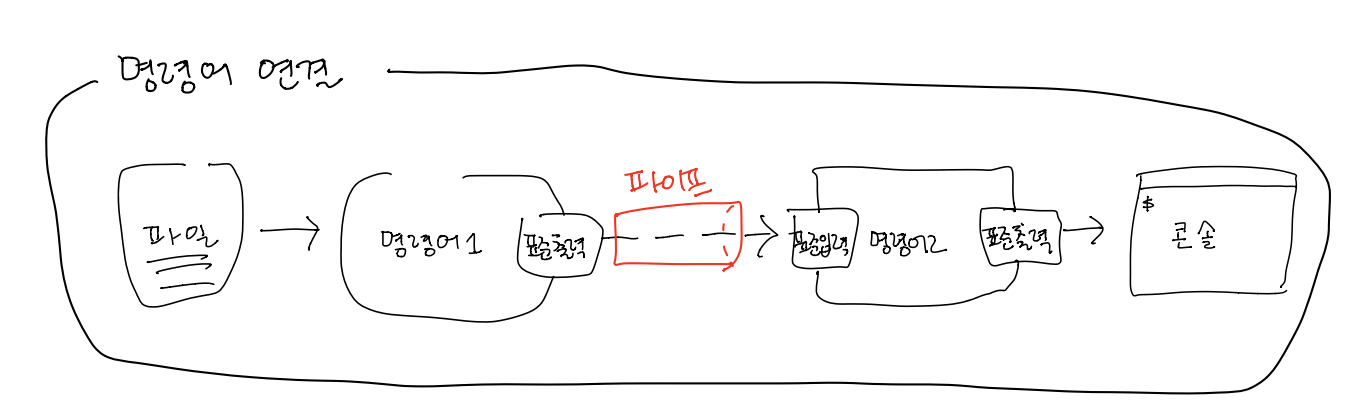
2. 파이프
3. 웹 페이지 추출

4. 문자코드
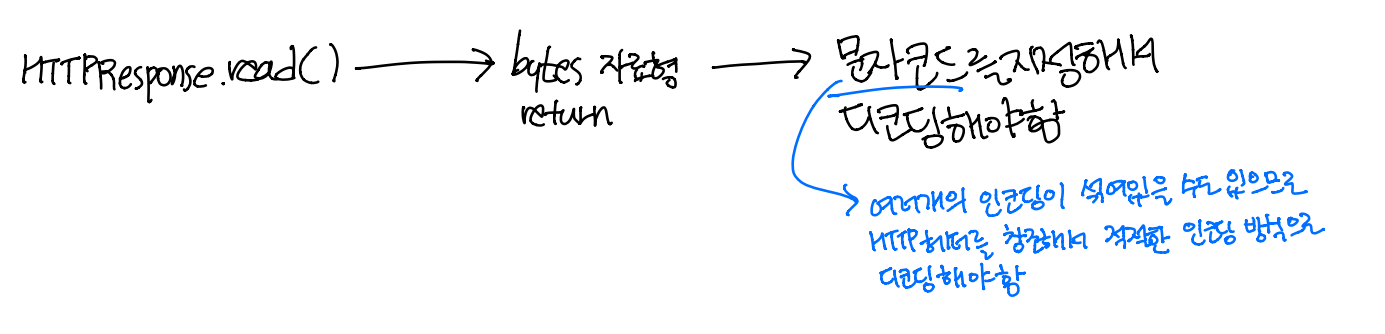
인코딩 방식(문자 코드) 정하는 방법
- HTTP 헤더에서 추출
- meta 태그에서 추출
5. 웹 페이지에서 데이터 추출
- 정규 표현식
- HTML을 단순한 문자열로 취급
- XML 파서
- XML 태그를 분석하고, 필요한 부분을 추출
- RSS처럼 많은 정보가 XML로 제공되기 떄문에 XML파서를 사용하면 편리
from xml.etree import ElementTree
6. SQLite
- 파일 기반의 관계형 데이터베이스
- 파일 쓰는데 걸리는 시간이 김
- 대용량의 데이터를 계속해서 쓰면 크롤러의 병목지점이 될 것
- 동시 처리 불가
7. Session
- 여러개의 페이지를 연속으로 크롤링할 때 사용하면 효율적
- HTTP 헤더 또는 Basic 인증 설정을 재사용 가능
- Cookie 자동 지원
- Session 객체를 사용해 같은 웹사이트에 여러번 요청하면 HTTP Keep-Alive 라는 접속 방식이 사용됨
- 한 번 확립한 TCP 요청을 계속 활용하므로 오버헤드가 되는 TCP 커넥션 확립 처리를 줄일 수 있어서 성능 향상을 기대할 수 있음
- 특히 Https의 경우 암호화를 위해 TLS/SSL 핸드셰이크를 하는데, 이때 HTTP Keep-Alive를 사용하면 서버 측 부하를 줄일 수 있음
s = requests.Session()
s.headers.update({'user-agent': 'my-crawler/1.0 (+id@domain)'})
r = s.get('http://hungry.com/')
8. HTML 스크레이핑
lxml
- C 언어로 작성된 XML 처리와 관련된 라이브러리인 libxml2와 libxslt의 파이썬 바인딩
- 굉장히 빠르게 동작
- 쉬운 API
Beautiful Soup
- 쉽고 직관적인 API
- 내부적으로 사용되는 파서를 목적에 맞게 변경 가능
Pyquery
- jQuery와 같은 인터페이스로 스크레이핑 할 수 있게 해줌
- 내부적으로 lxml을 사용
BeautifulSoup과 Pyquery 등의 lxml을 내부적으로 사용하는 라이브러리는 lxml을 사용하기 때문에 빠른 처리를 할 수 있지만, 결국에는 문제가 발생하면 lxml 지식이 필요함
9. RSS 스크레이핑
표준 라이브러리 ElementTree보다 더 쉽게 파싱할 수 있는 feedparser
RSS 피드의 버전 별 차이에 관계 없이 파싱할 수 있게 해줌
10 파이썬에서 MySQL 접속하기
- mysqlclient
- MySQL-python의 파이썬 3버전 포크
- 사용하기 쉽고 성능도 좋음
- MySQL 클라이언트 라이브러리인 libmysqlclient를 사용한 C 확장 라이브러리
- MySQL Connector / Python
- 오라클에서 제공하는 MySQL 공식 클라이언트
- PyMySQL
- 파이썬으로 만들어진 MySQL 클라이언트
11. 파이썬에서 MongoDB에 데이터 저장하기
- NoSQL의 일종으로 문서형이라고 부르는 데이터베이스
- 유연한 데이터 구조와 높은 쓰기 성능
- 계층 구조
- 하나의 데이터베이스는 하나의 콜렉션을 갖고, 하나의 콜렉션은 여러 개의 문서를 가짐
- 문서는 BSON이라고 부르는 JSON의 바이너리 형식으로 다룸(파이썬의 list, dict과 비슷한 데이터 구조)
- 미리 데이터 구조를 정의할 필요 없음
- 페이지에 따라 서로 다른 데이터 항목을 가질 수 있음
- 대량의 페이지를 동시에 병렬적으로 크롤링/스크레이핑하면 데이터베이스에 저장할 때 병목이 발생하는데 이를 MongoDB를 사용해서 줄일 수 있음
- 관계형 데이터베이스 대비 데이터 쓰기 성능이 높음
# mac
$ brew install mongodb
$ mongod --version
$ mkdir -p /data/db
$ mongod
- Ubuntu는 mongoDB또는 OS의 버전에 따라 차이가 있기때문에 아래의 공식 문서 참고
docs.mongodb.com/manual/tutorial/install-mongodb-on-ubuntu/
Install MongoDB Community Edition on Ubuntu — MongoDB Manual
docs.mongodb.com
# virtual env
$ pip install pymongo
# --------
from pymongo import MongoClient
'Crawling' 카테고리의 다른 글
| [크롤링/09]크롤러 분류 (0) | 2021.03.25 |
|---|---|
| [크롤링/08]퍼머링크와 데이터베이스 설계 (0) | 2021.03.25 |
| [크롤링/06] 인증이 필요한 페이지 (0) | 2021.03.22 |
| [크롤링/05]효율적인 크롤링 하는 방법 (0) | 2021.03.22 |
| [크롤링/04] HTTP 기본 총 정리 (0) | 2021.03.22 |
1. 표준 스트림과 리다이렉트
2. 파이프
3. 웹 페이지 추출
4. 문자코드
인코딩 방식(문자 코드) 정하는 방법
- HTTP 헤더에서 추출
- meta 태그에서 추출
5. 웹 페이지에서 데이터 추출
- 정규 표현식
- HTML을 단순한 문자열로 취급
- XML 파서
- XML 태그를 분석하고, 필요한 부분을 추출
- RSS처럼 많은 정보가 XML로 제공되기 떄문에 XML파서를 사용하면 편리
from xml.etree import ElementTree
6. SQLite
- 파일 기반의 관계형 데이터베이스
- 파일 쓰는데 걸리는 시간이 김
- 대용량의 데이터를 계속해서 쓰면 크롤러의 병목지점이 될 것
- 동시 처리 불가
7. Session
- 여러개의 페이지를 연속으로 크롤링할 때 사용하면 효율적
- HTTP 헤더 또는 Basic 인증 설정을 재사용 가능
- Cookie 자동 지원
- Session 객체를 사용해 같은 웹사이트에 여러번 요청하면 HTTP Keep-Alive 라는 접속 방식이 사용됨
- 한 번 확립한 TCP 요청을 계속 활용하므로 오버헤드가 되는 TCP 커넥션 확립 처리를 줄일 수 있어서 성능 향상을 기대할 수 있음
- 특히 Https의 경우 암호화를 위해 TLS/SSL 핸드셰이크를 하는데, 이때 HTTP Keep-Alive를 사용하면 서버 측 부하를 줄일 수 있음
s = requests.Session()
s.headers.update({'user-agent': 'my-crawler/1.0 (+id@domain)'})
r = s.get('http://hungry.com/')
8. HTML 스크레이핑
lxml
- C 언어로 작성된 XML 처리와 관련된 라이브러리인 libxml2와 libxslt의 파이썬 바인딩
- 굉장히 빠르게 동작
- 쉬운 API
Beautiful Soup
- 쉽고 직관적인 API
- 내부적으로 사용되는 파서를 목적에 맞게 변경 가능
Pyquery
- jQuery와 같은 인터페이스로 스크레이핑 할 수 있게 해줌
- 내부적으로 lxml을 사용
BeautifulSoup과 Pyquery 등의 lxml을 내부적으로 사용하는 라이브러리는 lxml을 사용하기 때문에 빠른 처리를 할 수 있지만, 결국에는 문제가 발생하면 lxml 지식이 필요함
9. RSS 스크레이핑
표준 라이브러리 ElementTree보다 더 쉽게 파싱할 수 있는 feedparser
RSS 피드의 버전 별 차이에 관계 없이 파싱할 수 있게 해줌
10 파이썬에서 MySQL 접속하기
- mysqlclient
- MySQL-python의 파이썬 3버전 포크
- 사용하기 쉽고 성능도 좋음
- MySQL 클라이언트 라이브러리인 libmysqlclient를 사용한 C 확장 라이브러리
- MySQL Connector / Python
- 오라클에서 제공하는 MySQL 공식 클라이언트
- PyMySQL
- 파이썬으로 만들어진 MySQL 클라이언트
11. 파이썬에서 MongoDB에 데이터 저장하기
- NoSQL의 일종으로 문서형이라고 부르는 데이터베이스
- 유연한 데이터 구조와 높은 쓰기 성능
- 계층 구조
- 하나의 데이터베이스는 하나의 콜렉션을 갖고, 하나의 콜렉션은 여러 개의 문서를 가짐
- 문서는 BSON이라고 부르는 JSON의 바이너리 형식으로 다룸(파이썬의 list, dict과 비슷한 데이터 구조)
- 미리 데이터 구조를 정의할 필요 없음
- 페이지에 따라 서로 다른 데이터 항목을 가질 수 있음
- 대량의 페이지를 동시에 병렬적으로 크롤링/스크레이핑하면 데이터베이스에 저장할 때 병목이 발생하는데 이를 MongoDB를 사용해서 줄일 수 있음
- 관계형 데이터베이스 대비 데이터 쓰기 성능이 높음
# mac
$ brew install mongodb
$ mongod --version
$ mkdir -p /data/db
$ mongod
- Ubuntu는 mongoDB또는 OS의 버전에 따라 차이가 있기때문에 아래의 공식 문서 참고
docs.mongodb.com/manual/tutorial/install-mongodb-on-ubuntu/
Install MongoDB Community Edition on Ubuntu — MongoDB Manual
docs.mongodb.com
# virtual env
$ pip install pymongo
# --------
from pymongo import MongoClient
'Crawling' 카테고리의 다른 글
| [크롤링/09]크롤러 분류 (0) | 2021.03.25 |
|---|---|
| [크롤링/08]퍼머링크와 데이터베이스 설계 (0) | 2021.03.25 |
| [크롤링/06] 인증이 필요한 페이지 (0) | 2021.03.22 |
| [크롤링/05]효율적인 크롤링 하는 방법 (0) | 2021.03.22 |
| [크롤링/04] HTTP 기본 총 정리 (0) | 2021.03.22 |