
✨Word2Vec이란?
Word2vec is a group of related models that are used to produce word embeddings. These models are shallow, two-layer neural networks that are trained to reconstruct linguistic contexts of words. Word2vec takes as its input a large corpus of text and produces a vector space, typically of several hundred dimensions, with each unique word in the corpus being assigned a corresponding vector in the space. Word vectors are positioned in the vector space such that words that share common contexts in the corpus are located close to one another in the space.[1]
Word2vec is a technique for natural language processing. The word2vec algorithm uses a neural network model to learn word associations from a large corpus of text. Once trained, such a model can detect synonymous words or suggest additional words for a partial sentence. As the name implies, word2vec represents each distinct word with a particular list of numbers called a vector. The vectors are chosen carefully such that a simple mathematical function (the cosine similarity between the vectors) indicates the level of semantic similarity between the words represented by those vectors. [2]
Word2vec은 구글에서 2013년에 발표한 자연어처리기법 중 하나로 8년이 지난 현재까지도 가장 많이 사용되는 워드 임베딩 모델 중 하나다.
Word2vec 알고리즘은 신경망 모델을 사용하여 큰 텍스트 말뭉치에서 단어 연관성을 학습한다. 한번 학습이 되면, 모델은 동의어를 탐지하거나 부분 문장에 대한 추가 단어를 제안할 수 있다. 이름에서 알 수 있듯이 word2vec는 벡터라고하는 특정 숫자의 목록을 사용하여 각각의 고유한 단어를 나타낸다. 벡터는 간단한 수학 함수(벡터 간의 코사인 유사도)가 해당 벡터가 나타내는 단어 간의 의미 유사성 수준을 나타내도록 신중하게 선택된다.
* corpus(말뭉치): 언어 연구를 위해 텍스트를 컴퓨터가 읽을 수 있는 형태로 모아 놓은 언어 자료. 언어 현실을 총체적으로 드러내 보여줄 수 있는 자료의 집합체로 매체, 시간, 공간, 주석 단계 등의 기준에 따라 다양한 종류가 있으며, 한 덩어리로 볼 수 있는 말의 뭉치라는 뜻이다.[3]
* cosine similarity(코사인 유사도): 내적공간의 두 벡터간 각도의 코사인값을 이용하여 측정된 벡터간의 유사한 정도
✨ CBOW와 Skip-gram
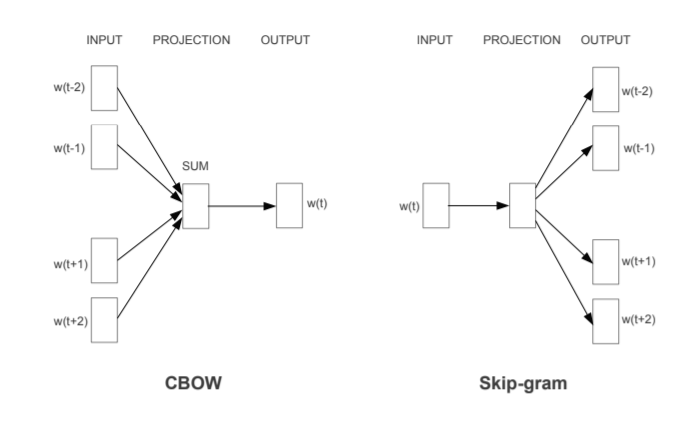
w[t]는 알고자 하는 단어고, w(t-2), w(t-1), w(t+1), w(t+2)는 주위를 둘러싼 단어다.
두 네트워크 모두 INPUT, PROJECTION, OUTPUT의 입력 레이어, 은닉 레이어, 출력 레이어로 구성되어 있다.
위의 그림처럼 CBOW는 주위를 둘러싼 단어에 기반해 현재 단어의 생성확률을 예측하는 네트워크고, Skip-gram은 현재 단어에 기반해 주위를 둘러싼 단어의 생성확률을 예측하는 네트워크다.
The dimensions of the input vector will be 1xV — where V is the number of words in the vocabulary — i.e one-hot representation of the word. The single hidden layer will have dimension VxE, where E is the size of the word embedding and is a hyper-parameter. The output from the hidden layer would be of the dimension 1xE, which we will feed into an softmax layer. The dimensions of the output layer will be 1xV, where each value in the vector will be the probability score of the target word at that position.[5]
입력 레이어에서 각 단어는 원-핫 인코딩으로 표현된다. 즉 모든 단어가 1xV(단어장에 나오는 단어의 개수)차원의 벡터로 표현되며, 각 단어에 대응되는 차원은 1이고 그 외의 차원은 모두 0이다.
단일 은닉 레이어는 차원 VxE를 가지며, 여기서 E는 단어 임베딩의 크기이며 하이퍼 파라미터이다. 은닉 레이어는 VxE차원 가중치 행렬을 통해 계산한다.
출력 레이어의 차원은 1xV이며, 벡터의 각 값에 대해 소프트맥스 활성화 함수를 사용하면 해당 위치에서 대상 단어의 생성확률이 된다.
모든 단어의 생성확률을 최대화하는 신경망의 가중치를 훈련해야 하는데, 가중치 학습은 backpropagation을 통해 이루어진다. 그러나 반복될 수록 속도가 느려져 이를 개선하기위해 Hierachical Softmax와 Negative Sampling이라는 방법이 나오기도 했다.
[1] Word2Vec 논문 주소 arxiv.org/pdf/1301.3781.pdf
[2] en.wikipedia.org/wiki/Word2vec
Word2vec - Wikipedia
Word2vec is a technique for natural language processing. The word2vec algorithm uses a neural network model to learn word associations from a large corpus of text. Once trained, such a model can detect synonymous words or suggest additional words for a par
en.wikipedia.org
[3] [네이버 지식백과] 말뭉치 [Corpus] (IT용어사전, 한국정보통신기술협회)
말뭉치
언어 연구를 위해 텍스트를 컴퓨터가 읽을 수 있는 형태로 모아 놓은 언어 자료. 언어 현실을 총체적으로 드러내 보여줄 수 있는 자료의 집합체로 매체, 시간, 공간, 주석 단계 등의 기준에 따라
terms.naver.com
[4] 코사인 유사도
코사인 유사도 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 코사인 유사도(― 類似度, 영어: cosine similarity)는 내적공간의 두 벡터간 각도의 코사인값을 이용하여 측정된 벡터간의 유사한 정도를 의미한다. 각도가 0°일 때
ko.wikipedia.org
[5] towardsdatascience.com/nlp-101-word2vec-skip-gram-and-cbow-93512ee24314
NLP 101: Word2Vec — Skip-gram and CBOW
A crash course in word embedding.
towardsdatascience.com
'Data' 카테고리의 다른 글
| 이미지 데이터가 부족할 때 생기는 문제(과적합; Over-fitting) 완화 방안 (0) | 2021.04.04 |
|---|---|
| [자연어처리]파이썬으로 데이터전처리하기 (0) | 2021.03.30 |
| [피처 엔지니어링/텍스트 마이닝]텍스트 표현 모델 (0) | 2021.03.27 |
| [피처 엔지니어링]피처 정규화 (0) | 2021.03.26 |
| [자연어처리]파이썬에서 워드, PDF, RSS 읽고 말뭉치(corpus) 생성하기 (1) | 2021.03.12 |
✨Word2Vec이란?
Word2vec is a group of related models that are used to produce word embeddings. These models are shallow, two-layer neural networks that are trained to reconstruct linguistic contexts of words. Word2vec takes as its input a large corpus of text and produces a vector space, typically of several hundred dimensions, with each unique word in the corpus being assigned a corresponding vector in the space. Word vectors are positioned in the vector space such that words that share common contexts in the corpus are located close to one another in the space.[1]
Word2vec is a technique for natural language processing. The word2vec algorithm uses a neural network model to learn word associations from a large corpus of text. Once trained, such a model can detect synonymous words or suggest additional words for a partial sentence. As the name implies, word2vec represents each distinct word with a particular list of numbers called a vector. The vectors are chosen carefully such that a simple mathematical function (the cosine similarity between the vectors) indicates the level of semantic similarity between the words represented by those vectors. [2]
Word2vec은 구글에서 2013년에 발표한 자연어처리기법 중 하나로 8년이 지난 현재까지도 가장 많이 사용되는 워드 임베딩 모델 중 하나다.
Word2vec 알고리즘은 신경망 모델을 사용하여 큰 텍스트 말뭉치에서 단어 연관성을 학습한다. 한번 학습이 되면, 모델은 동의어를 탐지하거나 부분 문장에 대한 추가 단어를 제안할 수 있다. 이름에서 알 수 있듯이 word2vec는 벡터라고하는 특정 숫자의 목록을 사용하여 각각의 고유한 단어를 나타낸다. 벡터는 간단한 수학 함수(벡터 간의 코사인 유사도)가 해당 벡터가 나타내는 단어 간의 의미 유사성 수준을 나타내도록 신중하게 선택된다.
* corpus(말뭉치): 언어 연구를 위해 텍스트를 컴퓨터가 읽을 수 있는 형태로 모아 놓은 언어 자료. 언어 현실을 총체적으로 드러내 보여줄 수 있는 자료의 집합체로 매체, 시간, 공간, 주석 단계 등의 기준에 따라 다양한 종류가 있으며, 한 덩어리로 볼 수 있는 말의 뭉치라는 뜻이다.[3]
* cosine similarity(코사인 유사도): 내적공간의 두 벡터간 각도의 코사인값을 이용하여 측정된 벡터간의 유사한 정도
✨ CBOW와 Skip-gram
w[t]는 알고자 하는 단어고, w(t-2), w(t-1), w(t+1), w(t+2)는 주위를 둘러싼 단어다.
두 네트워크 모두 INPUT, PROJECTION, OUTPUT의 입력 레이어, 은닉 레이어, 출력 레이어로 구성되어 있다.
위의 그림처럼 CBOW는 주위를 둘러싼 단어에 기반해 현재 단어의 생성확률을 예측하는 네트워크고, Skip-gram은 현재 단어에 기반해 주위를 둘러싼 단어의 생성확률을 예측하는 네트워크다.
The dimensions of the input vector will be 1xV — where V is the number of words in the vocabulary — i.e one-hot representation of the word. The single hidden layer will have dimension VxE, where E is the size of the word embedding and is a hyper-parameter. The output from the hidden layer would be of the dimension 1xE, which we will feed into an softmax layer. The dimensions of the output layer will be 1xV, where each value in the vector will be the probability score of the target word at that position.[5]
입력 레이어에서 각 단어는 원-핫 인코딩으로 표현된다. 즉 모든 단어가 1xV(단어장에 나오는 단어의 개수)차원의 벡터로 표현되며, 각 단어에 대응되는 차원은 1이고 그 외의 차원은 모두 0이다.
단일 은닉 레이어는 차원 VxE를 가지며, 여기서 E는 단어 임베딩의 크기이며 하이퍼 파라미터이다. 은닉 레이어는 VxE차원 가중치 행렬을 통해 계산한다.
출력 레이어의 차원은 1xV이며, 벡터의 각 값에 대해 소프트맥스 활성화 함수를 사용하면 해당 위치에서 대상 단어의 생성확률이 된다.
모든 단어의 생성확률을 최대화하는 신경망의 가중치를 훈련해야 하는데, 가중치 학습은 backpropagation을 통해 이루어진다. 그러나 반복될 수록 속도가 느려져 이를 개선하기위해 Hierachical Softmax와 Negative Sampling이라는 방법이 나오기도 했다.
[1] Word2Vec 논문 주소 arxiv.org/pdf/1301.3781.pdf
[2] en.wikipedia.org/wiki/Word2vec
Word2vec - Wikipedia
Word2vec is a technique for natural language processing. The word2vec algorithm uses a neural network model to learn word associations from a large corpus of text. Once trained, such a model can detect synonymous words or suggest additional words for a par
en.wikipedia.org
[3] [네이버 지식백과] 말뭉치 [Corpus] (IT용어사전, 한국정보통신기술협회)
말뭉치
언어 연구를 위해 텍스트를 컴퓨터가 읽을 수 있는 형태로 모아 놓은 언어 자료. 언어 현실을 총체적으로 드러내 보여줄 수 있는 자료의 집합체로 매체, 시간, 공간, 주석 단계 등의 기준에 따라
terms.naver.com
[4] 코사인 유사도
코사인 유사도 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 코사인 유사도(― 類似度, 영어: cosine similarity)는 내적공간의 두 벡터간 각도의 코사인값을 이용하여 측정된 벡터간의 유사한 정도를 의미한다. 각도가 0°일 때
ko.wikipedia.org
[5] towardsdatascience.com/nlp-101-word2vec-skip-gram-and-cbow-93512ee24314
NLP 101: Word2Vec — Skip-gram and CBOW
A crash course in word embedding.
towardsdatascience.com
'Data' 카테고리의 다른 글
| 이미지 데이터가 부족할 때 생기는 문제(과적합; Over-fitting) 완화 방안 (0) | 2021.04.04 |
|---|---|
| [자연어처리]파이썬으로 데이터전처리하기 (0) | 2021.03.30 |
| [피처 엔지니어링/텍스트 마이닝]텍스트 표현 모델 (0) | 2021.03.27 |
| [피처 엔지니어링]피처 정규화 (0) | 2021.03.26 |
| [자연어처리]파이썬에서 워드, PDF, RSS 읽고 말뭉치(corpus) 생성하기 (1) | 2021.03.12 |