
1. 피처 엔지니어링(Feature Engineering)이란?
"Feature engineering is the process of using domain knowledge to extract features from raw data via data mining techniques. These features can be used to improve the performance of machine learning algorithms."[1]
피처 엔지니어링은 최초 데이터(raw data)를 데이터 마이닝 기법을 통해 피처로 만들어서 머신 러닝 알고리즘의 성능을 향상시키는 일련의 과정이다.
"The purpose of a feature, other than being an attribute, would be much easier to understand in the context of a problem. A feature is a characteristic that might help when solving the problem."[1]
피처의 목적은 문제의 맥락에서 이해하면 더 쉽다. 피처는 문제를 푸는데 도움이 되는 특성이다.
"Features are important to predictive models and influence results.
It is asserted that feature engineering plays an important part of Kaggle competitions [4] and machine learning projects' success or failure."[1]
피처는 예측 모델에 중요하고 결과에 영향을 미친다. 피처 엔지니어링은 캐글 컴페티션이나 머신 러닝 프로젝트에서 성공 또는 실패를 가르는 중요한 부분을 맡고 있다.
피처 엔지니어링은 원석을 가공해서 보석을 만들어내는 것과 비슷한 것 같다. Raw data에서 noise와 redundancy를 제거(원석 가공)해서 더 효율적인 피처를 만들어서 예측 모델의 성능을 올려 문제를 해결하니까 말이다.
2. 피처 스케일링(Feature scaling)이란?
"Feature scaling is a method used to normalize the range of independent variables or features of data. In data processing, it is also known as data normalization and is generally performed during the data preprocessing step."[2]
피처 스케일링은 독립 변수 또는 데이터 피처의 범위를 정규화하는 데 사용되는 방법이다. 데이터 처리에서는 데이터 정규화라고도하며 일반적으로 데이터 전처리 단계에서 수행된다.
Since the range of values of raw data varies widely, in some machine learning algorithms, objective functions will not work properly without normalization. For example, many classifiers calculate the distance between two points by the Euclidean distance. If one of the features has a broad range of values, the distance will be governed by this particular feature. Therefore, the range of all features should be normalized so that each feature contributes approximately proportionately to the final distance.[2]
초기 데이터 값의 범위가 매우 다양하기 때문에 일부 기계 학습 알고리즘에서 목적 함수는 정규화 없이는 제대로 작동하지 않는다. 예를 들어, 많은 분류기가 유클리드 거리로 두 점 사이의 거리를 계산하는데, 피처 중 하나가 광범위한 값을 가지는 경우 거리는이 특정 기능에 의해 지배된다. 따라서 각 피처가 최종 거리에 대략적으로 비례하도록 모든 기능의 범위를 정규화해야한다.
초기 데이터 값의 범위가 매우 다양해 목적 함수가 정규화 없이는 제대로 작동하지 않는다는 것은 피처 정규화의 목적이 데이터 피처 사이의 차원 영향을 제거하는 것이라는 것을 말해준다. 데이터 피처 사이의 차원 영향을 제거하면 피처를 서로 비교할 수 있다.
예를 들어 키와 몸무게가 수명에 미치는 영향을 주제로 하는 연구를 하는데, 키와 몸무게에 사용하는 단위(m, kg)를 동시에 사용하면 분석 결과는 몸무게라는 피처에 지배되게 된다(이런걸 편향 bias 라고 한다). 일반적으로 키의 수치 범위는 1.6 ~ 1.8이고(0.3), 몸무게의 수치 범위는 50~90(40)이기 때문이다. 이를 정규화 하면 키와 몸무게를 비슷한 수치 구간으로 이동시킬 수 있다.
따라서 특정 피처에 편향되지 않고 결과를 얻기위해서는 데이터 정규화가 필요하다.
Another reason why feature scaling is applied is that gradient descent converges much faster with feature scaling than without it.[[2]
피처 스케일링을 사용하는 또다른 이유는 경사하강법의 수렴 속도를 (사용하지 않는 것보다)훨씬 빠르게 해주기 때문이다.
It's also important to apply feature scaling if regularization is used as part of the loss function (so that coefficients are penalized appropriately).[2]
정규화가 손실 함수의 일부로 사용되는 경우에도 계수가 적절하게 페널티를 받도록 피처 스케일링을 적용하는 것이 중요하다.
1) 피처 스케일링 하는 방법
참고로 피처 스케일링의 대상은 수치형 데이터다. 수치형 데이터를 피처 스케일링(정규화) 할 때 자주 사용하는 두가지 방법은 아래와 같다.
(1) Rescaling (min-max normalization)
Also known as min-max scaling or min-max normalization, is the simplest method and consists in rescaling the range of features to scale the range in [0, 1] or [−1, 1]. Selecting the target range depends on the nature of the data. The general formula for a min-max of [0, 1] is given as:[2]
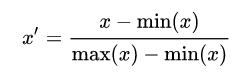
min-max 정규화 또는 min-max 스케일링으로 알려진 방법은 다양한 범주의 피처를 [0, 1] 또는 [-1, 1] 범위로 스케일링하는 가장 간단한 방법이다. 즉, 데이터를 동일한 수치 범위에 위치하도록 데이터를 동일한 비율로 축소하거나 확대한다. [0, 1]이나 [-1, 1]의 범위 선택은 데이터의 특성에 달려있다.
(2) Standardization (Z-score Normalization) 표준 정규화
In machine learning, we can handle various types of data, e.g. audio signals and pixel values for image data, and this data can include multiple dimensions. Feature standardization makes the values of each feature in the data have zero-mean (when subtracting the mean in the numerator) and unit-variance. This method is widely used for normalization in many machine learning algorithms (e.g., support vector machines, logistic regression, and artificial neural networks). The general method of calculation is to determine the distribution mean and standard deviation for each feature. Next we subtract the mean from each feature. Then we divide the values (mean is already subtracted) of each feature by its standard deviation.
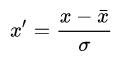
기계학습에서 우리는 다양한 종류의 데이터를 다룬다. 피처 표준화(또는 Z-score 정규화)는 각 피처가 평균이 0이고 표준편차가 1인 분포를 가지게 한다.
이 방법은 많은 기계 학습 알고리즘에서 정규화를 할 때 널리 사용된다. 대표적인 예로는 서포트 벡터 머신, 로지스틱 회귀, 신경망이 있다.
하지만 결정 트리 계열의 모델에서는 정규화가 필요없다. 결정 트리 노트 분열의 기준은 피처와 데이터 세트에 대한 정보이득비인데 이는 피처 정규화와 상관이 없기 때문이다(정규화는 피처에 대한 샘플의 정보 이득을 바꿀 수 없다).
[1]. en.wikipedia.org/wiki/Feature_engineering
Feature engineering - Wikipedia
Feature engineering is the process of using domain knowledge to extract features from raw data via data mining techniques. These features can be used to improve the performance of machine learning algorithms. Feature engineering can be considered as applie
en.wikipedia.org
[2]. en.wikipedia.org/wiki/Feature_scaling
Feature scaling - Wikipedia
Feature scaling is a method used to normalize the range of independent variables or features of data. In data processing, it is also known as data normalization and is generally performed during the data preprocessing step. Motivation[edit] Since the range
en.wikipedia.org
[3]. otexts.com/fppkr/missing-outliers.html
Forecasting: Principles and Practice (2nd ed)
2nd edition
Otexts.com
[4]. www.databaser.net/moniwiki/wiki.php/%EC%9D%B4%EC%83%81%EC%B9%98%EC%A0%9C%EA%B1%B0%EB%B0%A9%EB%B2%95
DataBaser.Net: 이상치 제거 방법
www.databaser.net
'Data' 카테고리의 다른 글
| 이미지 데이터가 부족할 때 생기는 문제(과적합; Over-fitting) 완화 방안 (0) | 2021.04.04 |
|---|---|
| [자연어처리]파이썬으로 데이터전처리하기 (0) | 2021.03.30 |
| [피처엔지니어링]Word2Vec (0) | 2021.03.28 |
| [피처 엔지니어링/텍스트 마이닝]텍스트 표현 모델 (0) | 2021.03.27 |
| [자연어처리]파이썬에서 워드, PDF, RSS 읽고 말뭉치(corpus) 생성하기 (1) | 2021.03.12 |